Ref to triton tutorial
triton compiler 负责CTA内部的线程排布以及内存排布,CTA外部(即如何排布CTA)是由使用者去tune的。这篇triton的教程介绍了如何提高基于GPU 缓存的data reuse。 在GPU架构中,L1 cache是SM内的,L2 cache是全局的,所以基于L1的优化是triton compiler的事情,L2是用户去考虑的。 基于triton的mm的伪代码 实现如下:
# Do in parallel
for m in range(0, M, BLOCK_SIZE_M):
# Do in parallel
for n in range(0, N, BLOCK_SIZE_N):
acc = zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=float32)
for k in range(0, K, BLOCK_SIZE_K):
a = A[m : m+BLOCK_SIZE_M, k : k+BLOCK_SIZE_K]
b = B[k : k+BLOCK_SIZE_K, n : n+BLOCK_SIZE_N]
acc += dot(a, b)
C[m : m+BLOCK_SIZE_M, n : n+BLOCK_SIZE_N] = acc
逻辑上每个CTA的执行是并行的,但实际上,每个CTA都会放在SM上执行,物理上不一定是完全并行的,因此CTA的排布(执行编号)可能会影响cache hit(试想,如果某时刻SMs上的CTA从完全不同的RAM中读数据,那么cache miss是会很严重,因此起不到data reuse的效果;反之,如果SMs之间会读取相同的内存块,那么cache hit就会提高,不用频繁从RAM中读数据)。 为方便分析,不妨假设SM数量为9,对于一个分块后tile_m=tile_n=9的mm,同时会有9个CTA在SM上执行,即同时计算C的9个blocks,最简单的CTA layout是根据raw-major去排布,如下代码所示:
pid = triton.program_id(0);
grid_m = (M + BLOCK_SIZE_M - 1) // BLOCK_SIZE_M;
grid_n = (N + BLOCK_SIZE_N - 1) // BLOCK_SIZE_N;
pid_m = pid / grid_n;
pid_n = pid % grid_n;
pid 是CTA的编号,往往也是SM调度的顺序。pid_m和pid_n是当前编号pid的CTA对应的需要计算的block,其效果如下图:
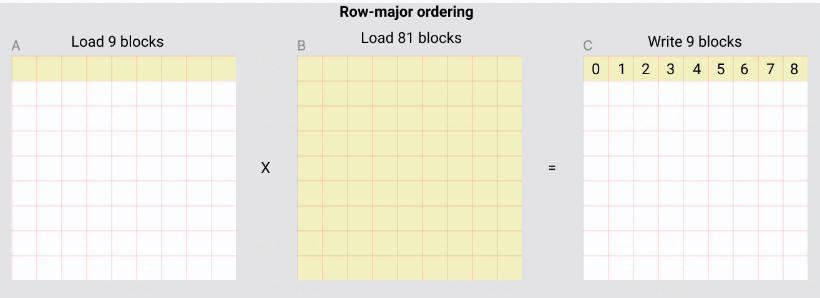
即CTA的layout(CTA与block的映射关系)是行主序的。为了计算C的9个block,如果没有cache,那么需要load A的9个block 9次,B的9个block 9次,即一共load 162次 block。但因为有 L2 cache,SM从A中访问的是相同内存,所以会复用cache的数据,所以实际对A的9个block只从global memory 读了一次,但不同SM从B中读的blocks都是不同的,无法利用L2 cache,所以需要从B中读81个block,AB合计读90个block。 为了提高L2 cache hit rate,容易想到调整当前9个CTA对应的layout,尽量提高cache hit。 triton教程介绍的是名为 Grouped ordering 的排布方式,如下图所示:
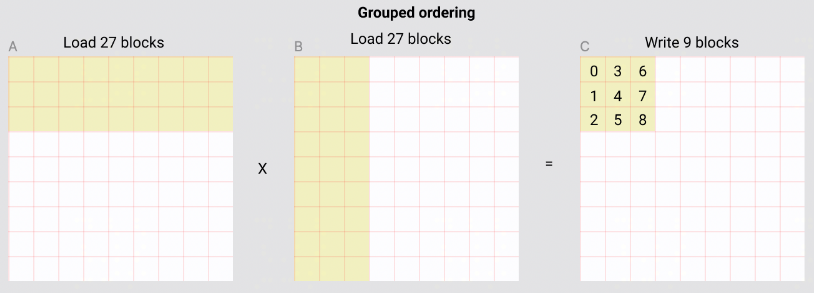
如果物理上每个时刻有9个SM并发,那么此时从A和B中读的数据都会被reuse 2次,即读block的数量减少了2/3,优化成了162/3=54次。 计算CTA的layout的伪代码如下:
# Program ID
pid = tl.program_id(axis=0)
# Number of program ids along the M axis
num_pid_m = tl.cdiv(M, BLOCK_SIZE_M)
# Number of programs ids along the N axis
num_pid_n = tl.cdiv(N, BLOCK_SIZE_N)
# Number of programs in group
num_pid_in_group = GROUP_SIZE_M * num_pid_n
# Id of the group this program is in
group_id = pid // num_pid_in_group
# Row-id of the first program in the group
first_pid_m = group_id * GROUP_SIZE_M
# If `num_pid_m` isn't divisible by `GROUP_SIZE_M`, the last group is smaller
group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M)
# *Within groups*, programs are ordered in a column-major order
# Row-id of the program in the *launch grid*
pid_m = first_pid_m + (pid % group_size_m)
# Col-id of the program in the *launch grid*
pid_n = (pid % num_pid_in_group) // group_size_m
每GROUP_SIZE_M行为一个Group,每个group内是列主序的。因此layout要先计算当前pid映射到哪个group,然后计算在group中的位置。其中,超参GROUP_SIZE_M需要tune,显然这个参数与L2 cache的size以及SM数量有关。triton教程中将GROUP_SIZE_M设置成8,A100有108个SM,因此预设的是每次SMs计算一个8x?的blocks。按理说应该计算sqrt(num_sm)xsqrt(num_sm)比较合适,约等于10x10,所以将GROUP_SIZE_M设置成8也算合理。